Every visualization is an opportunity to tell a story. I don’t always take advantage of that opportunity, opting instead to just “display data” in a simple and user-friendly layout. Granted, sometimes that is what I’m asked to do (business users do love their data tables), but I can say that whenever I approach a visualization as a storyteller, I am more pleased with the results and, candidly, I think the final visualization is always better.
Getting acquainted with the story
- The focus of the project is explicitly young black men.
- The focus of the training is technical, particularly coding.
- African Americans are underrepresented in tech (both in terms of education and employment) and missing out on the growing opportunities in that field.
So, in a sentence: Young black males are missing out on the growing opportunities in tech because they are not receiving the education they need to participate.
Selecting the story elements
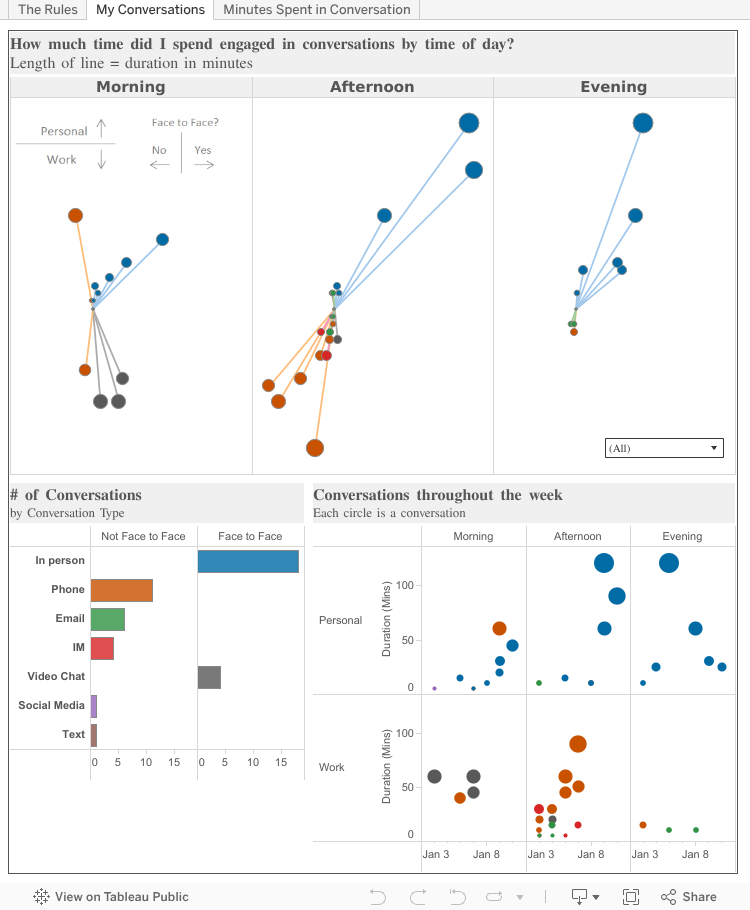
The Central Image
- It needed to be available for me to use, i.e. not have restricted usage rights. I didn’t always pay attention to this when I created visualizations, but I now know to make sure any image I use has been shared by the photographer in a way that allows me to use it without violating copyright. Many photos are shared under Creative Commons, so the available pool is still pretty big, but it is both prudent and respectful to make sure any image you use is one you should use.
-
- An easy way to check is to use the Google Image search tools and only select images that are labeled for re-use.

-
- Some sites (like Flickr, where I ended up finding the photo I used) also allow you to see the usage rights for an image. Clicking the “Some rights reserved” will tell you exactly what you can and cannot do with the image.

- I wanted it to be monochrome and have no background. I know that you can desaturate any color photo and remove backgrounds, but those post-production steps don’t always produce the best results, so I was looking for a photo that I could use as-is.
- I wanted a photo that would look good big. Some photos shared online are available only in smaller sizes that get very pixelated when you enlarge them.
I eventually found the perfect photo and went about obscuring one half of the young man’s face. There are a number of ways to do this. Pooja Gahndi (who inspired me to use semi-transparent images in my vizzes) uses MS Word, but since I have a Mac without MS Office, I do my photo prep in the free software GIMP.


Once you have the semi-transparent image file, simply open it inside of Tableau by dragging an Image object on a dashboard tab and selecting the file you just saved. In my case, I also set the dashboard background to black so that the image blended in the way I wanted it to.

The Color Palette
I wanted to let the Hidden Genius logo drive the color palette. As such, I decided to only use monochrome colors (i.e. gradients of black, white and grey) and the specific shade of green used in the logo (which I sampled via the color picker tool in Tableau and added as a custom palette).
In particular, I wanted to use the green as an accent color to identify the focus areas of the story, which were African American men and the Tech field (specifically coding/computers). So, in each of the charts and text boxes, I only used that green to format elements that related to either African Americans or the computer industry.


Floating and Faux-Transparency
Now that I had my central image and overall color palette, it was time to start adding the other elements to my dashboard. This is where floating and floating order become indispensable design tools, since they allow you to have precise control over layout and how the different elements on your dashboard interact.
I wanted to divide my canvas based on the split nature of the photo. The left side would highlight the “Hidden” nature of African Americans in STEM fields (both in terms of employment and education), and the right side would focus on the opportunity available to the untapped potential of this target demographic.
So, first came the title, which is just two text boxes floated on top of the photo. Their placement and formatting are very deliberate.
- I chose to make the “Hidden” text box smaller than the “Genius” text box (80 pixels high vs. 100) and used more subdued colors to shift the visual emphasis to the right.
- I placed the “Genius” text box atop the young man’s brain, as that is where the untapped potential resides. This also ties in with the quote I chose for the bottom portion of the viz, namely “There’s value in you, your brain, and what you’re going to create.”

- I used a skinny text box (height of 1-2 pixels) to connect the two text boxes, which helps underscore that this project guides the young men from obscurity to visible success.

The rest of the left side is comprised of a couple sheets and a few text boxes. Beyond the choice of color palette described above, I only made a few additional formatting decisions:
- I set the Worksheet shading to ‘None’ so that they inherited the background color from the dashboard (i.e. black).

- I made sure the worksheets were lower in floating order than the photo. You can do this by selecting and dragging the objects where you want them on the Layout panel. This is the way you make it appear that the sheet background is transparent. In actuality, the photo is just on top of the sheet, but since you’ve set the opacity of the photo very low, it doesn’t obscure the chart.
- I positioned the line chart so that the young man’s right eye could still be seen.

The right side followed a similar approach, only I didn’t need to worry about floating order as much since I didn’t want any of the elements (the snippet of code, the bar chart) to be on top of the young man’s face. I just nudged things around the canvas until my OCD was satisfied. This mostly involved using the Position and Size settings in the Layout pane to ensure each element was where I wanted it to be.

Finishing Touches
Sometimes I like to place borders around my text boxes, and sometimes I don’t. Sometimes, though, I only want a border on one side of a text box, as a way of providing a little separation between the text box and the background without being too “heavy”. To do this I can’t use the standard formatting options, since it’s all or nothing when it comes to borders (i.e. all four sides or no sides). In these cases, you can use another text box (with a width of 1-2 pixels) and simply place it alongside the edge of the other text box.
 |
| Text box without borders |
 |
| Text box with a skinny text box acting as a left-hand border |
And finally, since there were a number of data sources used for this viz, I wanted an easy way for the viewer to see where the data came from (and maybe get a little more contextual information) without having to go to another tab or reference a single info pop-up in one corner of the viz. So instead I created a few info sheets and placed them directly next to the specific data I wanted sourced.

Each info sheet contains a single measure (I created a measure called ‘One’ which is just the number 1) with a Mark Type of Shape. For the shape I used an information icon downloaded from Google. Read this post in case you don’t know how to add custom shapes to Tableau. It’s very easy.

I set each sheet to have a width and height of 20 pixels and placed them onto the dashboard canvas. I then added the necessary reference information to each sheet’s tool tip. Since I wanted people to be able to hover over these sheets and read the information in the tool-tip, I made sure that these info sheets were higher in the floating order than the main image.

___________________
Each viewer will ultimately decide whether all of these design choices aided the visualization. Was the story clear? Was it compelling? Did I make it easy for them to engage with the data? I certainly hope so. But I will know that I did my best job when I can clearly articulate why each element was added to the visualization and what purpose it served in telling the story I wanted to tell. And by being able to do that, I believe I increase my chances of connecting with my audience and making a successful visualization.
Thanks for reading.









































































































![\mathbf{B}(t) = (1 - t)[(1 - t) \mathbf P_0 + t \mathbf P_1] + t [(1 - t) \mathbf P_1 + t \mathbf P_2] \mbox{ , } 0 \le t \le 1](https://upload.wikimedia.org/math/d/1/2/d128a258d310c67addf3bf877f0a3ba4.png)